
AI and computing power have become highly dynamic, with applications spreading across various sectors and industries. It’s a great time to discuss whether LLM servers or services should be on-premise or cloud-based. Let’s dive into this topic on “Sembang AIoT”!
An LLM, or Large Language Model, in AI is like a very advanced, super-smart robot that can read, understand, and write human language. Here’s a simpler way to explain it:
Smart Robot Brain: Think of an LLM as a brainy robot that has read millions of books, articles, and websites. It has learned a lot about how people talk and write.
Text Generation: This robot can help you write. If you give it a few words or a topic, it can create stories, essays, or even chat with you like a human would.
Answering Questions: You can ask it questions about almost anything, and it will try to give you a helpful answer based on what it has learned.
Translation: If you need to translate something from one language to another, this robot can do that too.
Summarization: Have a long article and want just the main points? This robot can read it and give you a short summary.
Real-Life Uses:
Customer Service: When you chat with a help desk online, sometimes it’s this robot answering your questions.
Writing Help: Writers use it to get ideas, fix grammar, or even write entire paragraphs.
Learning and Teaching: It can help students understand tough subjects by explaining things in simpler terms.
Imagine it as a helpful assistant that’s always ready to help you with anything related to reading, writing, or understanding text.
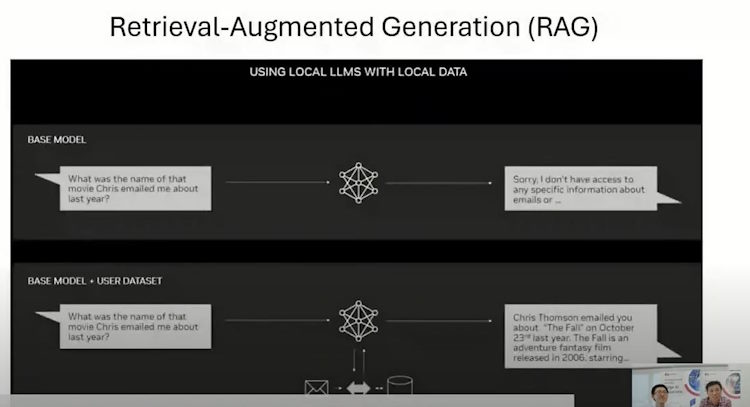
During the “Sembang AIoT” live session, we showcased the on-premise LLM using an Axiomtek industrial rack-mount server running NVIDIA’s Chat RTX. One of the features within this LLM is responsible for RAG (Retrieval-Augmented Generation). But what exactly is RAG?
In the context of chat applications like RTX (presumably referring to a specific chat platform or technology, possibly leveraging NVIDIA RTX technology for AI), RAG stands for Retrieval-Augmented Generation. Here’s what that means in simpler terms:
Retrieval-Augmented Generation (RAG)
Combining Retrieval and Generation:
Retrieval: This part involves searching through a large database of information to find relevant pieces of text or data that can help answer a question or provide context.
Generation: This part involves creating new text or responses based on the information retrieved, using an AI model like a Large Language Model (LLM).
How It Works:
When you ask a question in a chat, the system first retrieves relevant information from its database or knowledge base.
It then generates a response that combines this retrieved information with its own understanding and language skills to provide a more accurate and helpful answer.
Why It’s Useful:
Accuracy: By retrieving actual facts or relevant data, the system can provide more accurate and reliable answers.
Context: It can pull in specific information related to your query, making the response more relevant and tailored.
Efficiency: It combines the strengths of searching a database and generating natural-sounding text, making interactions smoother and more informative.
Example in Chat RTX
Imagine you’re using a chat service that uses RAG. Here’s how it might work:
You ask, “What are the symptoms of the flu?”
The system searches its medical database and retrieves relevant information about flu symptoms.
It then generates a response like: “The common symptoms of the flu include fever, chills, muscle aches, cough, congestion, runny nose, headaches, and fatigue.”
By leveraging RAG, the chat system can provide more precise and contextually appropriate responses, making your interaction more effective and informative.
On-Premise LLM Vs Cloud based LLM
In “Sembang AIoT,” let’s delve deeper into these aspects to determine which solution best fits your organization’s needs!
On-Premise LLM vs. Cloud-Based LLM: Pros and Cons
On-Premise LLM
Pros:
Enhanced Control: You have complete control over your data, which can be crucial for industries with strict data privacy regulations (e.g., healthcare, finance).
Reduced Risk: Minimizes the risk of data breaches as data does not leave your premises.
Customization:
Tailored Solutions: Greater flexibility to customize the LLM to suit specific needs and integrate with existing systems.
Optimization: Can be optimized for specific tasks and performance requirements.
Latency:
Faster Response Times: Lower latency as the data does not need to travel over the internet, which is beneficial for real-time applications.
Cons:
Cost:
High Initial Investment: Significant upfront costs for hardware, infrastructure, and setup.
Maintenance Expenses: Ongoing costs for maintenance, updates, and IT support.
Scalability:
Limited Flexibility: Scaling up can be challenging and expensive as it requires additional hardware and resources.
Capacity Planning: Requires careful planning to avoid underutilization or overloading of resources.
Technical Expertise:
Required Skill Set: Needs a skilled IT team to manage and maintain the infrastructure.
Cloud-Based LLM
Pros:
Scalability:
Flexible Scaling: Easily scales up or down based on demand without the need for additional hardware.
Elastic Resources: Pay-as-you-go model allows for cost-effective scaling.
Cost Efficiency:
Lower Initial Costs: No need for significant upfront investment in hardware.
Operational Expenses: Predictable monthly expenses based on usage.
Accessibility and Collaboration:
Remote Access: Accessible from anywhere, which supports remote work and collaboration.
Managed Services: The cloud provider handles maintenance, updates, and security.
Cons:
Data Security and Privacy:
Potential Vulnerabilities: Data is stored off-premises, which can raise concerns about data breaches and compliance with regulations.
Third-Party Dependence: Relies on the security measures of the cloud provider.
Latency:
Variable Latency: Can be higher compared to on-premise solutions, depending on internet speed and cloud provider infrastructure.
Customization:
Limited Customization: Less flexibility to customize compared to on-premise solutions.
Standardized Solutions: May need to conform to the provider’s environment and limitations.
Conclusion:-
Choosing between on-premise and cloud-based LLMs depends on your specific needs, including data security requirements, budget, scalability needs, and technical capabilities. On-premise solutions offer greater control and customization but come with higher costs and maintenance requirements. Cloud-based solutions provide flexibility, scalability, and lower initial costs but may pose data security concerns and less customization.
watch us on Youtube:-
Discover the future of work with AI and its impact on jobs. Explore the benefits and challenges of integrating AI tools in companies. Learn how AI can enhance productivity and create new opportunities for growth. Join the discussion on the future of jobs in the era of AI.